
Every organization wants to become AI-driven.
Boards are asking about generative AI. Business teams are experimenting with copilots. Technology teams are building proofs of concept. Vendors are promising automation, intelligence, and faster decision-making.
But inside many organizations, the reality is more uncomfortable.
The AI ambition is moving faster than the data foundation.
Data is still fragmented. Ownership is unclear. Definitions vary across teams. Quality issues are tolerated because “the dashboard mostly works.” Governance is seen as compliance work, not a business capability. Metadata is incomplete. Lineage is patchy. Access controls are inconsistent. And critical business knowledge often lives in documents, emails, spreadsheets, and people’s heads.
AI does not hide these problems.
It exposes them.
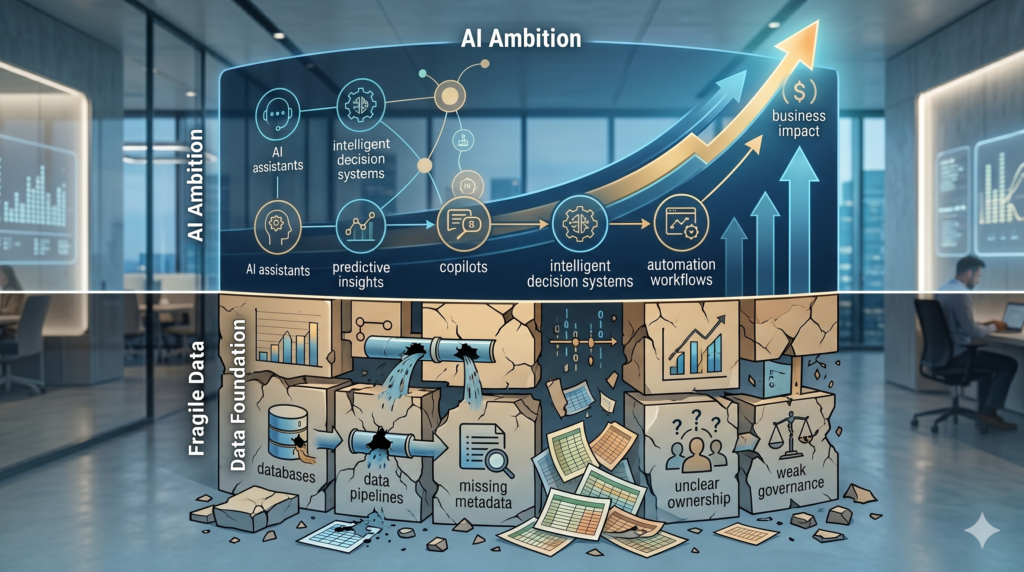
In fact, AI makes weak data foundations more visible because AI systems depend on context, quality, trust, permissions, and repeatability. A dashboard can sometimes survive messy data. A machine learning model might partially compensate for it. But a generative AI assistant that gives confident answers from unclear, stale, or poorly governed data can quickly become a business risk.
That is why the role of the data leader is changing.
The next generation of data leaders will not be measured only by how many platforms they modernized, how many pipelines they built, or how many dashboards they delivered. They will be measured by whether their organization can safely, responsibly, and repeatedly turn data into intelligence.
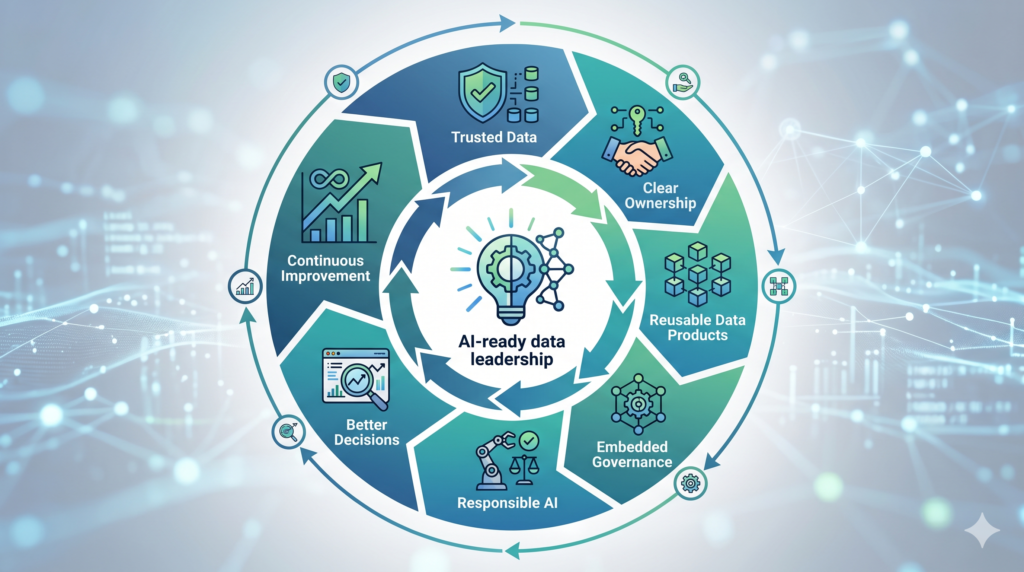
That is the work of the AI-ready data leader.
AI Readiness Is Not Just a Technology Problem
Many organizations still treat AI readiness as a model, tooling, or platform decision.
Which large language model should we use?
Should we build or buy?
Should we use a cloud-native AI platform?
Do we need vector databases?
Should we adopt agents?
These are valid questions. But they are not the first questions.
The first questions are more fundamental:
Can we trust the data?
Do we know who owns it?
Can we explain where it came from?
Can we control who can access it?
Can we detect when it changes?
Can we reuse it across multiple AI and analytics use cases?
Can business users understand its meaning?
Without those answers, AI remains trapped in experimentation.
This is already becoming visible across the industry. McKinsey’s 2025 State of AI research notes that AI use continues to grow, but many organizations have still not scaled AI broadly across the enterprise. It also highlights that risk and data governance are among the more centralized elements of AI deployment. (McKinsey & Company)
Deloitte’s 2026 State of AI in the Enterprise report similarly points to the shift from pilot to scale, noting that worker access to AI rose by 50% in 2025 and that expectations for production-scale AI are increasing. (Deloitte)
The message is clear: AI adoption is no longer the hard part. Scaling AI safely and usefully is the hard part.
And scaling AI is a data leadership challenge.
From Data Delivery to Data Readiness
Traditional data leadership has often focused on delivery.
- Deliver the warehouse.
- Deliver the lakehouse.
- Deliver the dashboard.
- Deliver the report.
- Deliver the migration.
- Deliver the pipeline.
AI changes the focus from delivery to readiness.
A data product is no longer just an asset consumed by analysts. It may become context for a chatbot, grounding for a retrieval-augmented generation system, input for an AI agent, training data for a model, or evidence for an automated decision.
That means the data leader must think beyond storage and movement.
They must ask whether data is:
- Discoverable: Can people and systems find the right data?
- Understandable: Is the business meaning clear?
- Trustworthy: Is quality measured and visible?
- Governed: Are ownership, access, and policies defined?
- Reusable: Can it support multiple analytical and AI use cases?
- Observable: Can teams detect drift, breakage, and unexpected change?
- Explainable: Can outputs be traced back to source, logic, and context?
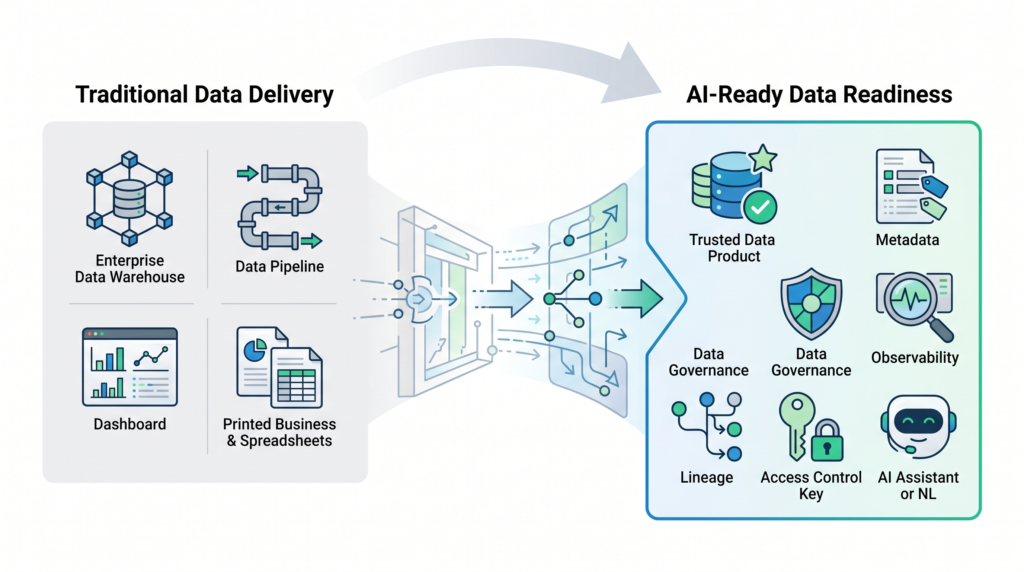
This is the shift from managing data platforms to enabling intelligent systems.
The AI-Ready Data Leader Thinks in Products, Not Projects
AI does not scale well when every use case starts from scratch.
One team cleans customer data for a churn model. Another cleans similar customer data for personalization. A third prepares it again for a customer service chatbot. Each team defines fields differently, handles quality issues differently, and documents assumptions differently.
This is expensive. It is slow. It creates risk.
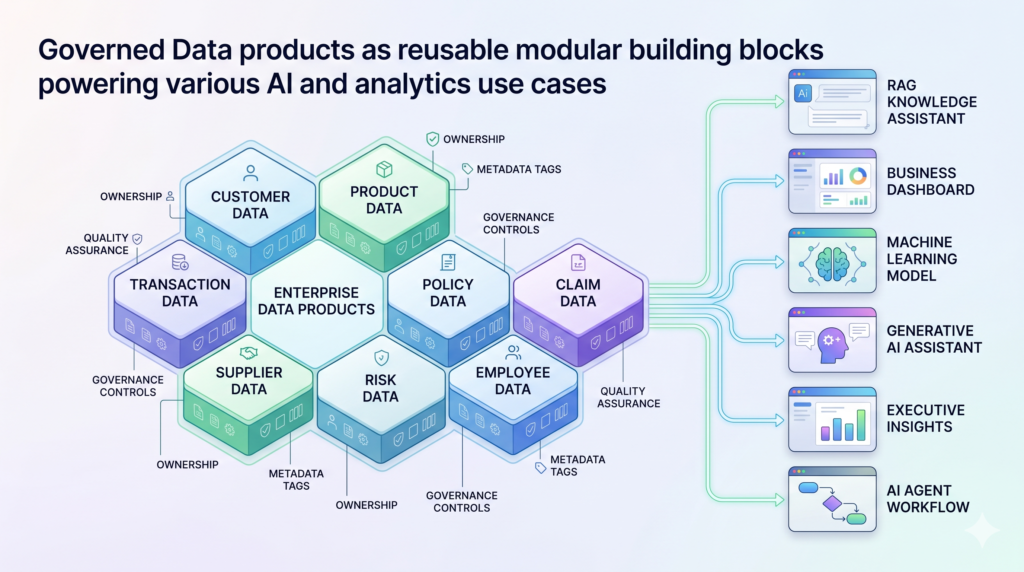
The AI-ready data leader moves the organization toward reusable data products.
A data product is not just a table with a nicer name. It is a governed, documented, owned, quality-managed data asset designed for consumption. It has a clear domain owner, defined semantics, quality expectations, usage policies, lineage, and support mechanisms.
For AI, this product thinking becomes even more important.
AI systems need reliable business context. They need curated knowledge. They need trusted datasets. They need permission-aware access. They need metadata that explains meaning, sensitivity, freshness, and limitations.
Without data products, AI teams keep rebuilding foundations.
With data products, AI teams can compose solutions faster and with more confidence.
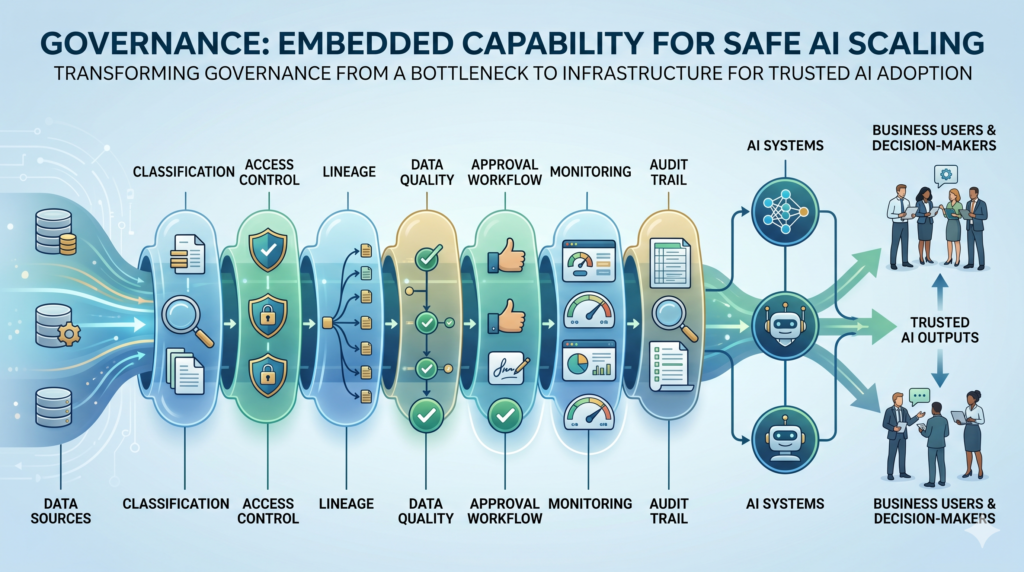
Governance Becomes an Accelerator, Not a Brake
Governance has often been positioned as a control function.
- Review this.
- Approve that.
- Restrict access.
- Enforce policy.
- Meet compliance requirements.
But AI changes the governance conversation.
When AI systems generate answers, summarize documents, recommend actions, classify risk, or automate decisions, governance becomes part of the product architecture. It is not something added after the system is built. It is part of how the system earns trust.
The NIST AI Risk Management Framework was created to help organizations manage risks to individuals, organizations, and society from AI systems. Its core functions, govern-map-measure-manage, are useful reminders that AI risk is not only a model problem; it is an operating model problem. (NIST)
Regulatory expectations are also becoming more concrete. The EU AI Act entered into force on August 1, 2024, and is scheduled to become fully applicable on August 2, 2026, with some exceptions applying earlier. (Digital Strategy)
This matters for data leaders because AI governance cannot be separated from data governance.
- A model cannot be responsible if the data feeding it is unknown.
- An AI assistant cannot be trusted if it retrieves unauthorized documents.
- An automated decision cannot be explained if lineage is missing.
- A risk control cannot work if ownership is unclear.
The AI-ready data leader does not treat governance as paperwork.
They treat governance as infrastructure.
The New Data Leadership Questions
The AI-ready data leader asks different questions from the traditional data leader.
Not only: “Do we have a data platform?”
But: “Can our data platform support trusted AI consumption?”
Not only: “Do we have dashboards?”
But: “Do our metrics have consistent definitions across humans, reports, and AI systems?”
Not only: “Do we have data quality rules?”
But: “Are quality expectations visible, measurable, and connected to business impact?”
Not only: “Do we have access controls?”
But: “Can AI systems respect permissions at retrieval, generation, and action time?”
Not only: “Do we have a data catalog?”
But: “Does our catalog help people and AI systems understand context, ownership, lineage, and usage constraints?”
Not only: “Are we compliant?”
But: “Can we prove that our AI-enabled decisions are governed, traceable, and monitored?”
These questions move data leadership from platform management to organizational intelligence.
Five Capabilities Every AI-Ready Data Leader Must Build
1. Data Quality as a Business Discipline
AI-ready organizations do not treat data quality as a technical cleanup activity.
They define quality in business terms.
For example, “customer email must not be null” is a technical rule. But “customer contactability must be reliable enough for service, marketing, and compliance use cases” is a business expectation.
The AI-ready data leader connects quality to outcomes: revenue leakage, operational risk, customer experience, regulatory exposure, and AI trust.
2. Metadata as the Context Layer for AI
Metadata is no longer just catalog information.
It becomes the context layer that helps people and AI systems understand data meaning, ownership, sensitivity, lineage, freshness, and usage limits.
For generative AI, metadata is especially important. Retrieval systems need to know which documents are current, which are confidential, which business domain they belong to, and which user is allowed to access them.
Poor metadata leads to poor AI context.
3. Data Products as Reusable AI Building Blocks
AI-ready data leaders organize high-value data around domains and consumption patterns.
Customer, product, policy, claim, supplier, transaction, employee, and risk data should not be rebuilt independently for every AI initiative.
They should become reusable, governed data products that serve analytics, reporting, machine learning, and generative AI.
4. Governance Embedded into Delivery
AI governance cannot sit outside delivery teams.
Policies need to become controls. Controls need to become workflows. Workflows need to become platform capabilities.
This includes access control, lineage, data classification, human approval, model monitoring, prompt and response logging where appropriate, and clear accountability for AI use cases.
5. Operating Model Alignment
The hardest part of AI readiness is not the tool stack.
It is the operating model.
- Who owns the data?
- Who approves AI use cases?
- Who monitors quality?
- Who manages risk?
- Who defines business meaning?
- Who responds when AI output is wrong?
- Who decides whether an AI system is ready for production?
The AI-ready data leader makes these responsibilities explicit.
The Mindset Shift
The traditional data leader often thinks in terms of systems.
The AI-ready data leader thinks in terms of trust.
- Trust in data.
- Trust in definitions.
- Trust in access.
- Trust in lineage.
- Trust in outputs.
- Trust in decisions.
This does not mean slowing down innovation. It means creating the conditions where innovation can scale.
Because the organizations that win with AI will not simply be the ones with the most experiments. They will be the ones that can move from experiments to trusted, repeatable, governed intelligence.
That requires strong data leadership.
Closing Thought
AI readiness is not achieved by buying an AI platform.
It is achieved when an organization can confidently answer:
- We know what data we have.
- We know what it means.
- We know who owns it.
- We know who can use it.
- We know how good it is.
- We know where it came from.
- We know how it is being used.
- We know how to monitor it.
- We know how to govern it.
That is the foundation of AI at scale.
And that is why the future of AI leadership begins with data leadership.
The AI-ready data leader is not just preparing data for AI.
They are preparing the organization for intelligent, trusted, and accountable decision-making.